
Advanced Training Topics
This documentation applies to version 2.1 of the Training Editor. On older versions of Bixby Developer Studio, selecting training in a subfolder of the resources folder might open the legacy editor. This editor is deprecated, and support for it was removed in Bixby Studio 8.21.1.
If what you're looking at doesn't match the screenshots in this documentation, update to the newest version of Bixby Developer Studio!
This document discusses more advanced features of Bixby Developer Studio's Training Editor. You should be familiar with how to create training entries before going on to these topics. If you haven't read Training for Natural Language yet, start there.
Roles
Sometimes, Bixby needs more context to fully understand values. For instance, the following utterance includes two airport codes: "find flights from SFO to YUL leaving this December 22nd". The codes are both the same AirportCode concept, but one has a role of DepartureAirport and one has a role of ArrivalAirport.
To add roles to utterances, highlight the relevant parts of the utterances and click + Add Role. You can add the node for the role in the right-hand sidebar. Once added, the role's annotation shows up as a purple outline.
Now that you've added these roles to the training example, the Bixby planner can distinguish that the second airport is using a type that is a role-of the parent type. You can learn more about role assignment.
Another place roles are used is when two or more values can be used together to specify a single item. For instance, consider the utterance "Remove the XL t-shirt from my cart" in the shirt example capsule: "XL" is a Size and "t-shirt" is a SearchTerm; together, they have the role of RemovedItem.
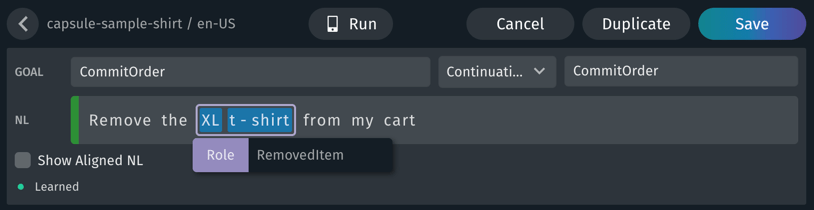
With two already annotated values such as in this example, you will not be able to highlight both values at once to add the role. Instead, click on either value, then click + Add Role. The outline that appears around the selected value can be moved with the mouse to highlight the entire role phrase.
Training on Properties
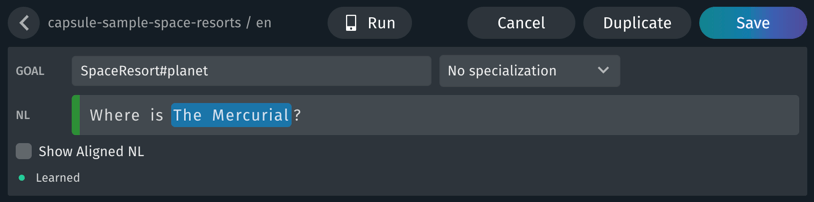
There are instances when a user utterance targets a property of a goal rather than the goal itself. This is called property projection. For example, when a user asks the space resorts capsule "Where is The Mercurial", the intent of the utterance is asking for the location of a specific space resort, not information about the space resort as a whole.
In cases like this, where the utterance asks for a specific part or "property" of the goal concept, you can add specific training entries to target properties like this.
To add a property to a target goal, specify the property with a hash (#) notation: in this case, SpaceResort#planet. The structured concept SpaceResort has a property for the total (planet). By making this the goal, you assert that the utterance's intent and goal is the planet (planet) in the Space Resort model (SpaceResort).
Flags
When adding training, there are some utterances in which it is difficult to precisely annotate values. Take, for example, the following utterance: "reserve a table for 3 people for dinner next Friday". We can annotate the number of people the reservation is for ("3") and the requested time ("dinner next Friday"). But we need to add an extra parameter to this search query: we should filter out restaurants that are not currently accepting reservations.
In cases like this, when you cannot clarify the intent by annotating specific words or adding additional vocabulary, you can use flags to give clues to Bixby. Flags are a way to annotate the entire utterance rather than a specific word or phrase within it. Just like annotations, flags can provide values or routes.
In this example from the shirt capsule, "Remove the XL shirt from my cart" demonstrates several training concepts, including a flag:
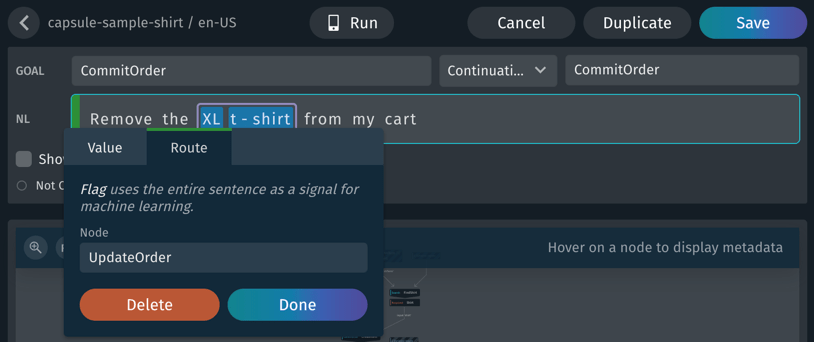
- "XL" is annotated as a
Size - "t-shirt" is annotated as a
SearchTerm - "XL t-shirt" is together given a role of
RemovedItem - The entire utterance has a route flag of
UpdateOrder, specifying an action to route through on the way to the goal ofCommitOrder
To add a flag, click the bar to the left of the NL field. (The entire field will be highlighted when you are over it.) Then select the "Value" or "Route" tab. You will be prompted in the sidebar for the necessary information, such as the route's node, or the value's node and form.
While value flags are supported with concepts of type enum, boolean, integer and decimal, enum and boolean will work best as they are enumerated types.
If you are flagging training examples with a boolean, you must use all lower case. For example, do use v:ReservationIntent:true and don't use something like v:ReservationIntent:True.
Routes
A route tells the planner to go through a "waypoint" on the way to the goal, so it can factor in more information or prompt for more information.
For instance, take the utterance "Is it raining near me?" To train this, you could add a flag signaling that the weather condition is rain: set the node weather.WeatherCondition to the value rain. Then you would add a route of geo.CurrentLocation to let Bixby know to factor in the current user location.
Another example of using a route is a continuation that needs to prompt for more information. For example, in the restaurant reservation example, the user might give Bixby the utterance, "change the party size"; Bixby will need to prompt for the new size:
[g:ChangeReservation:continue:Reserve, r:UpdatePartySize] Change the party sizeThe UpdatePartySize route lets Bixby know that it needs to prompt the user.
Routes can be attached to individual values, but are more commonly associated with flags on a whole utterance. In either case, you still need to annotate specific words in utterances as values. Additionally, when you can substitute specific words within a sentence (such as "cheap", "inexpensive", and "affordable"), normal training still offers the benefit of vocabulary.
Routes can make your capsule's logic harder to follow, and in many cases you can design your capsule so routes are unnecessary. The previous continuation example could be implemented so that UpdatePartySize is a valid goal, for instance, or party size could itself be a value supplied to ChangeReservation. Read Training Best Practices for more guidance.
Batch Actions
You can select multiple training entries for certain batch operations:
- Click the "more actions" menu (the drop-down accessed with the "•••" button at the right-hand side of the search bar) to choose Select All or Select None.
- Click the checkmark that appears when you hover over the top left corner of each individual training entry to select or deselect that entry.
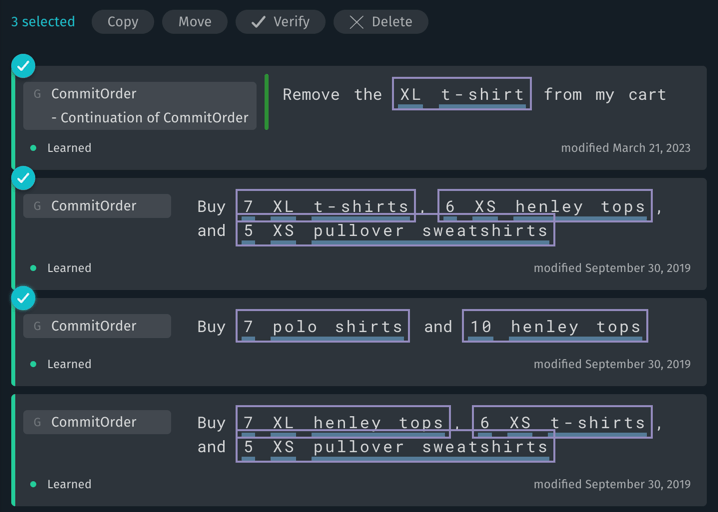
The available batch actions when one or more entries are selected include the following:
- Copy: Copy the selected entries to another target. You can choose to copy them to a different locale, language, or device target. Copying entries duplicates them: the entries remain in the current target, and are also created in the new target.
- Move: Move the selected entries to another target. You can choose to move them to a different locale, language, or device target. Moving entries removes them from the current target.
- Verify: Verify the plans of the selected entries.
- Delete: Delete the selected entries.
Searches and Filters
The training editor offers several ways to search through your trained utterances.
- Use the Statistics sidebar on the right to quickly filter by status, issues, goals, and specializations. The filter search field performs "fuzzy" matching on item names.
- Use the search bar at the top of the screen to search for words and phrases within training entries.
- The search bar performs exact matching, with support for
*as a wildcard glob match.My*will match bothMyConceptandMyAction. - Search is case-insensitive:
Samsung,samsung, andSAMSUNGare all equivalent. - Exclude a word from a search query by prefixing it with the
-character:Show me the weather in san -bernardinowill matchshow me the weather in san joseandshow me the weather in san franciscobut notshow me the weather in san bernardino.
- The search bar performs exact matching, with support for
- You can use scope prefixes in search text to refine searches, using keywords in the following table.
| Search Scope | Syntax | Synonyms | Example |
|---|---|---|---|
| Entry with training ID | id:<training-id> | training-id | id:t-687v0fxyy5580vipz1ab39gx |
| Entries with exact NL | text:<nl-text> | txt, phrase | text:weather |
| Entries with specific node | node:<nodeid> | match | node:viv.weather.WeatherCondition |
| Entries with specific value | value:<nodeid> | v | value:viv.weather.WeatherCondition |
| Entries with a specific flag | flag:<nodeid> | f | flag:viv.food.Diet |
| Entries with a specific route | route:<nodeid> | rte, r | route:viv.geo.CurrentLocation |
| Entries with a specific goal | goal:<nodeid> | g | goal:viv.weather.Weather |
| Entries with a specific continuation | continuation:<nodeid> | continue, continuation-of | continuation:viv.weather.Weather |
| Entries with a specific role | role:<nodeid> | – | role:viv.air.ArrivalAirport |
| Entries with a specific prompt | prompt:<nodeid> | prompt-for | prompt:viv.air.DepartureDate |
| Entries with a specific tag | tag:<text> | tagged | tag:needs-modeling |
| Entries with at least one of a specific field type | has:<field-type> | is | has:role |
| Entries with a specific learning status | status:<status> | – | status:learned |
Valid fields for the has: scope are value, route, role, continuation, pattern, prompt, tag, enabled, disabled, and flag. This scope searches for entries that have any field of that type, rather than specific contents in that field.
Valid learning statuses are learned, not-learned, and not-compiled.
You can combine search scopes to filter more narrowly. To search for training with a goal of weather.Weather related to humidity tomorrow, you could use goal:weather.Weather humid tomorrow.
Training Evaluation
Bixby generalizes from your training examples to understand utterances it hasn't been explicitly trained on. When you create training examples, your goals should be the following:
- Create training examples that cover all of your capsule's use cases
- Create the minimum number of training examples to cover those cases, to avoid "overfitting" in ways that make it difficult to generalize
- Avoid examples that cause regressions in the understanding of essential utterances
It can be difficult to manually evaluate your training examples. Instead of manual testing, you can create test sets, collections of Aligned NL, that can be analyzed for effectiveness with the Training Evaluation Dashboard.
Dashboard
To open the Dashboard for creating a new test set or work with existing sets, select Training Evaluation in Bixby Developer Studio's File sidebar.
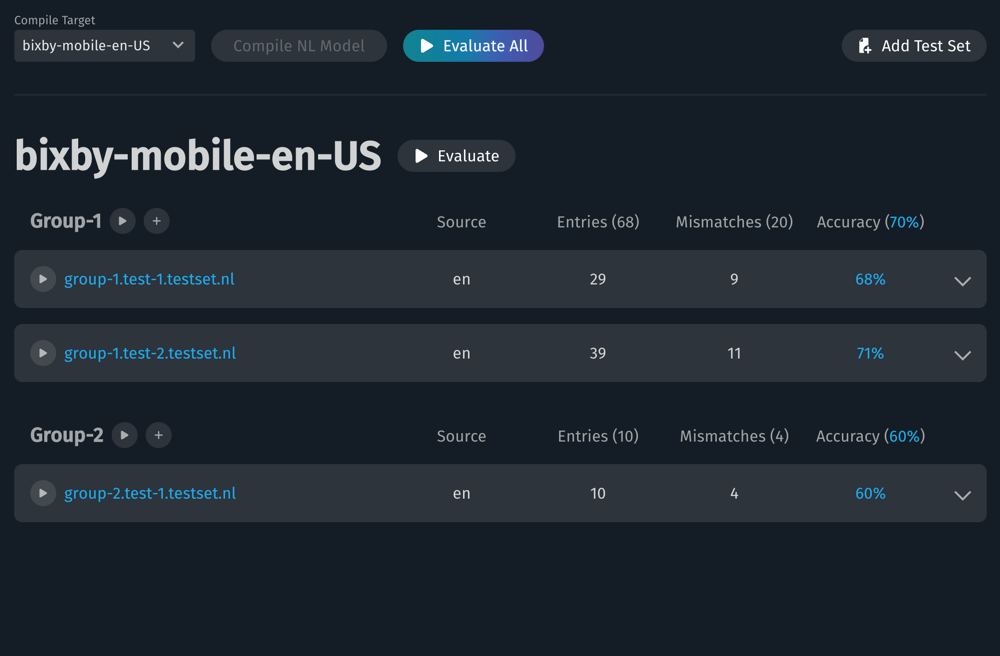
You must compile the NL model before performing any evaluation. If the model needs compilation, the Compile NL Model button will be enabled.
- To evaluate all of the test sets, click Evaluate All.
- To evaluate a group of test sets, click the play button by the group's name. (See Test Sets for details about how to group test sets.)
- To evaluate a specific test set, click the play button by that set's filename.
- To create a new test set, click Add Test Set. Click + by a group name to add a test specifically to that group.
- To edit an existing test set, click its filename.
After a test set has been evaluated, the dashboard will display the number of mismatches, entries whose Aligned NL in the test set does not match the data received after evaluation. Click on the test set row's disclosure triangle, at the right end of the row, to display the mismatches in more detail, with the mismatched elements in each line highlighted.
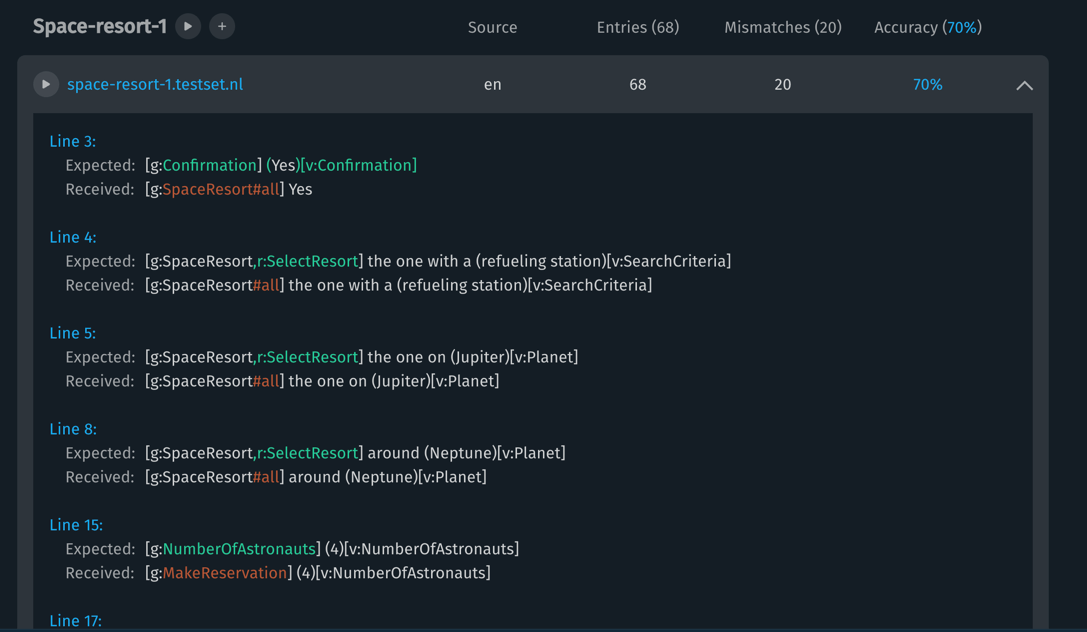
A mismatch in the evaluation dashboard indicates that one of the examples in the test set specified an expected goal or value for the utterance that does not match the received goal or value, meaning the training model did not predict the goal or value correctly. When a mismatch occurs, you should add variations of the mismatch to the test set and re-evaluate it to try to diagnose the problem. A goal might be undertrained, for instance, or you might need to add vocabulary.
You can get a summary overview of expected goals versus received goals in an evaluated set or group by clicking the accuracy percentage, which will open the confusion matrix.
Test Sets
A test set is a file of Aligned NL utterances, each on their own line, such as the following:
[g:SpaceResort#all] Find hotels near (Mars)[v:Planet:Mars]
[g:SpaceResort#all:continue] with a (spa)[v:SearchCriteria]
[g:CheckStatus] Do I have an upcoming space trip?You can create a single test set file for your capsule, or create multiple files to group related utterances into different test sets.
Create a new test set from the Evaluation Dashboard by clicking Add Test Set. Click + by a group name to add a test specifically to that group.
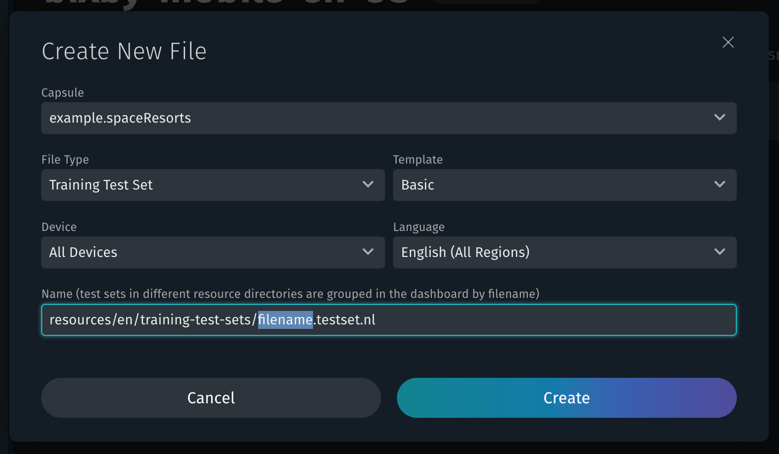
The Create New File pop-up will prompt you to create a new test set file in the appropriate directory. Select the device and language, enter the new filename, and click Create. Leave the extension as .testset.nl. The new test set will open in Bixby Studio for editing.
To group tests together, use a two-part filename of this format:
group-name.test-set-name.testset.nlFor example, if the filename is dev.search.testset.nl, the test set will be named search, and it will appear in the group dev. Tests in a group can be run and evaluated together, or they can be run and evaluated individually.
Tests are always grouped together based on the first segment of the filename (the name up to the first . character). A filename of test1.testset.nl creates a group named test1 with one test in it.
Each non-blank line of the file must be a valid Aligned NL utterance, or a single-line comment beginning with //. Autocomplete is available as you type.
You can edit an existing test set by clicking on its name in the Evaluation Dashboard, or opening it from the Files sidebar. To delete a test set, use the Files sidebar.
The Confusion Matrix
A confusion matrix is a table that summarizes the accuracy of a classification model, comparing the expected results against the actual results. The training evaluation dashboard can generate a confusion matrix of the goals for a test set or a group of sets. To view the matrix, click on the accuracy percentage of an individual test or of the overall group.
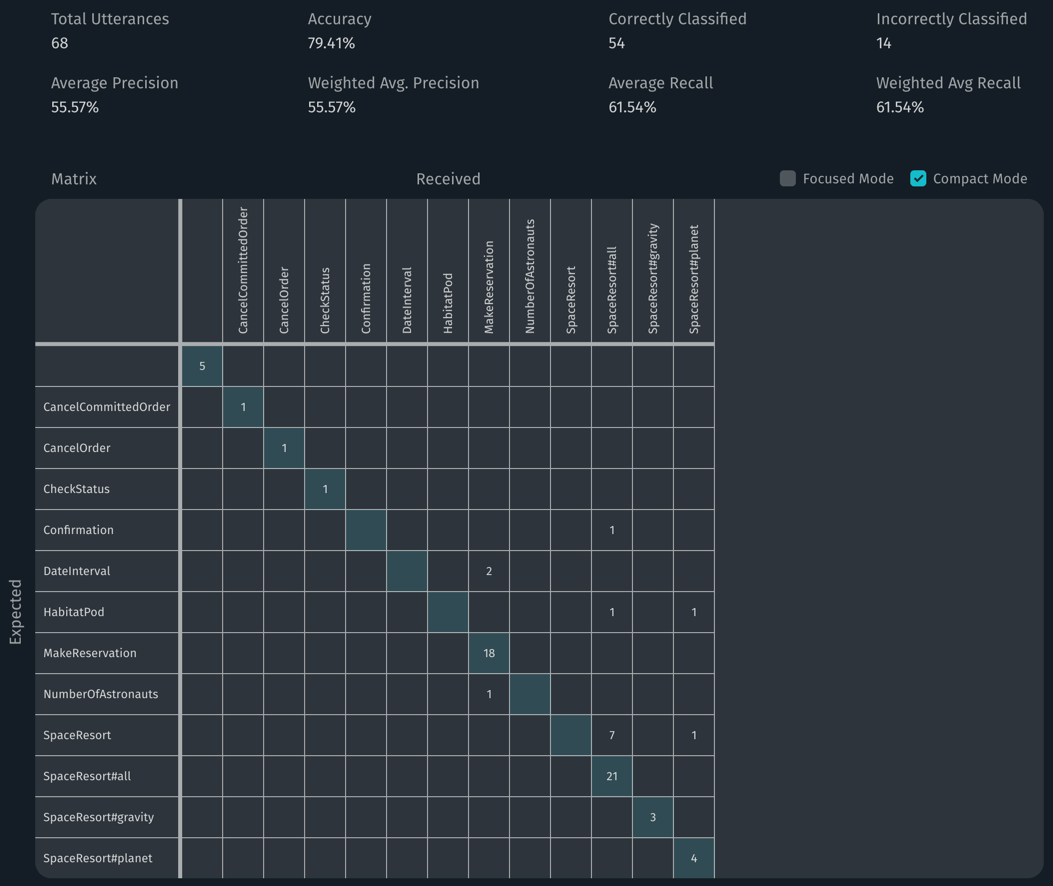
- The rows represent the expected goals for the Aligned NL in a test set or group of sets.
- The columns represent the received goals for the Aligned NL evaluated by the model.
- The numbers in the matrix indicate how many goals are an accurate match or a mismatch.
Accurate matches occur when the goals for the expected and received utterances are the same. These squares in the confusion matrix are shaded, forming a diagonal line from upper left to lower right. In the example above, there were 18 accurate matches for MakeReservation. Numbers outside the highlighted squares indicate mismatches, cases where the goal specified in the row was interpreted by the model as the goal specified in the column.
When you find mismatches, they indicate potential problems with your training model or, possibly, with the provided test data. The utterance being tested might be too specific, or not specific enough. The matrix can also give you an overview of what goals might need more training examples.
In addition to the matrix, overall statistics are presented at the top of the chart, and a summary table of goals is produced showing accuracy information for each goal.
The statistics at the top of the confusion matrix include the following information:
- Total Utterances: The total number of Aligned NL in the test set or group of sets.
- Accuracy: The ratio of correctly classified divided by total utterances.
- Correctly Classified: The number of received goals that match the expected goals.
- Incorrectly Classified: The number of mismatches (received goals that don't match the expected goals).
- Average Precision: The average of the precision for each goal. This indicates the total amount of false positives, the number of times the model incorrectly evaluated the presence of the goal.
- Weighted Avg. Precision: The average of the precision for each goal while incorporating goal weights.
- Average Recall: The average of the recall for each goal. This indicates the total amount of false negatives, the number of times the model incorrectly evaluated the absence of a goal.
- Weighted Avg Recall: The average of the recall for each goal while incorporating goal weights.
Scroll past the matrix to see the summary table. The summary includes the following information:
- Received (FP): The number of received goals for the Aligned NL evaluated by the model. The number in parentheses is the number of false positives. In the matrix, false positives are numbers in the column above and below the shaded square.
- Expected (FN): The number of expected goals for the Aligned NL evaluated by the model. The number in parentheses is the number of false negatives. In the matrix, false negatives are numbers in the row to the left and right of the shaded square.
- Correct: The number of received goals that matched the expected goals. These are the numbers in the shaded squares in the matrix.
- Precision: The ratio of correctly matched goals divided by the received goals. Precision indicates the amount of false positives; ideally this is 1, indicating none.
- Recall: The ratio of correctly matched goals divided by the expected goals. Recall indicates the amount of false negatives; ideally this is 1, indicating none.
- F1-Score: The harmonic mean of precision and recall. Ideally this is 1, meaning there are no false positives or false negatives.
Even if a test set has a precision, recall, and F1-Score of 1, the model will always have the potential for false positives and negatives in practice.
Display Modes
You can change the display of the confusion matrix with the checkboxes to the upper right of the table.
- Check Focused Mode to show only the table, hiding the overall summary at the top and the per-goal summary table at the bottom.
- Check Compact Mode to shrink the table to display more of it on screen at once.
Goal Weights
By default, all tests are given an equal weight in evaluation, indicating they are all of identical relative importance. You can adjust the weighting of specific goals by editing a JSON file. Click Edit Goal Weights to open training-tests-goal-weights.json in a new editor tab.
When the file opens, it has an empty JSON dictionary object. To adjust goal weights, add new key-value pairs to this dictionary, with the keys matching goal names in your test sets and the values being new goal values, relative to 1. For instance, if you give the MakeReservation goal a weight of 5, this indicates it should be weighted at five times the importance of other goals.
{
"MakeReservation": "5"
}When you evaluate a test set or group after making this edit, you will see the new weighting reflected in the Weighted Average Precision and Weighted Average Recall results. You might want to adjust goal weighting to reflect how common specific goals are in user requests; for instance, users might be more likely to ask Bixby to set an alarm than to modify an existing alarm.
Weighting values can be either strings or numeric values. Decimals (such as 4.5 or 0.75) are allowed.
Exporting
You can export the confusion matrix, along with the overall summary and per-goal summary, as a CSV (comma-separated value) file by clicking Export CSV.
The generated CSV file is not a single table, but contains all three tables shown in the goal confusion matrix. It can be opened directly in a spreadsheet program such as Microsoft Excel, but might need to be edited for importing into other utilities.
Video Tutorial: Training Evaluation
The following tutorial demonstrates the training evaluation dashboard's features and usage.
Troubleshooting
Bixby Studio informs you if your training examples have issues. However, if you have a large number of training entries, it can sometimes be difficult to quickly find a training entry causing an issue. This section discusses how to find any issues and what certain training entry statuses mean.
Training Entry Statuses
Training entries usually exist in one of three states:
- Learned: Bixby has learned, and can execute, this training entry.
- Not Learned: Bixby does not have enough information to learn from this training entry.
- Not Compiled: The NL model needs to be recompiled before this entry can be learned.
When you add training entries, they will usually start as Not Compiled. This status applies as long as Bixby hasn't generated NL models for those entries.
To generate new NL models when you add new examples or update old ones, click Compile NL Model. When the models are generated, Bixby changes the label of the learned utterances to Learned. If your training entry is similar enough to previous training examples, Bixby might label it as Learned even before you compile the model.
Changes in other training or vocabulary can cause an utterance to revert to a Not Learned or Not Compiled state. If Bixby can't learn a specific example, consider adding similar training examples, reviewing existing training entries for conflicting utterances, or updating vocabulary.
There are four other possible status values for training entries:
- Disabled: The training entry is not scanned for errors and not trained.
- Illegal Plan: The training entry has unsatisfied input constraints or unconsumed signals. This means that the intent of what you have trained does not match with the way the models have been designed to work. See Illegal Plans.
- Unverified Plan: The training entry's current plan differs in a nontrivial way from the plan at the time this entry was saved. This can happen when model changes make the training entry's plan behave differently from the last time it was saved. You can resolve this by ensuring the plan for the entry is correct and recompiling the NL model, or by running Verify All Plans.
- Incomplete: These are generally semantic, such as the lack of a goal or referencing Node IDs that do not exist.
Find Training Entry Issues
You can quickly find issues using the search sidebar on the Training Sets Screen. Check the Issues subheading for categories of warnings and errors.
If you are submitting a capsule and one of your training entries is throwing an error, you can search for that specific error using the id: search scope.
Open the submission page and select your failed example.
Select "Capsule Interpreter Training".
On the log page, look for the entries causing the issue:
-------------------------------------------------------------------- (4) Entries in state NOT_LEARNED (ERROR: actively causing rejection) -------------------------------------------------------------------- View all items in category (copy the search between the markers into the training tool) >>>> BEGIN COPY <<<< id:t-jcvrft523b1j3iwzti7wx2zq7,t-q1b5nsdjb2clwy8fkhre80ecg,t-wczwvczrezonkmp2djlaj9wcj,t-v7s9drvf7whsbfxup9n9rw2j8 >>>> END COPY <<<<Copy the failure ID(s), as directed in the training window.
Search for your training example with the ID by pasting the ID into the search bar. This will find the entry blocking the submission.
How to fix your training example depends on how you've tagged the example and how your modeling is set up. There might be multiple ways to fix an issue. See Training Best Practices.
Illegal Plans
An illegal plan occurs when the graph that Bixby's planner has created for a specific training entry cannot be run. There are several possible reasons why a plan might be illegal:
- The models have input constraints which cannot be satisfied.
- The graph has an unused signal, which appears as a detached node.
- The plan contains an uninstantiated
plan-behavior (Always)input. - The plan contains three or more consecutive lossy action nodes chained together with no intervening nodes.
A "lossy" activity is one that has the potential of losing user-provided signals, such as a search action, fetch action, or transactions. You can often resolve the illegal plan error by adding a route, or making one of the actions a different non-lossy type, such as Calculate or Resolver, though certain actions types should be used for specific situations. An illegal plan normally indicates a problem with your capsule's modeling; in general, you don't want to force Bixby to create long chains of actions in order to fulfill user requests.
Plan Verification
You can clear "Unverified Plan" statuses by selecting the Verify All Plans command in the "more actions" menu (the drop-down accessed with the "•••" button at the right-hand side of the search bar). This command asserts that the plans for all complete, legal, and enabled entries are correct. It will create a new plan from the Aligned NL for each entry, based on the current state of your capsule's models, vocabulary, and other data.
The training status of each entry might change after running this command. Disabled plans will not be verified.
Training Entries Budget
The training entries budget presents a list of capsule targets for your capsule in overview form, showing you how many entries are applicable to each target, the source folders those entries are contained in, and the "training budget" used by each target. To navigate to the budget screen, click the button with the bar graph icon near the top of the training summary page.

A target has a "budget" of 2,000 training entries. This is computed as the sum of all entries that apply to that target. The budget screen lists the budget available for each target, as well as the parent targets that are part of that budget. For instance, if you had both bixby-mobile-en-US and bixby-mobile-en-GB targets, the en language set would be shown as applying to both of them. Training entries for patterns do not count towards this budget.
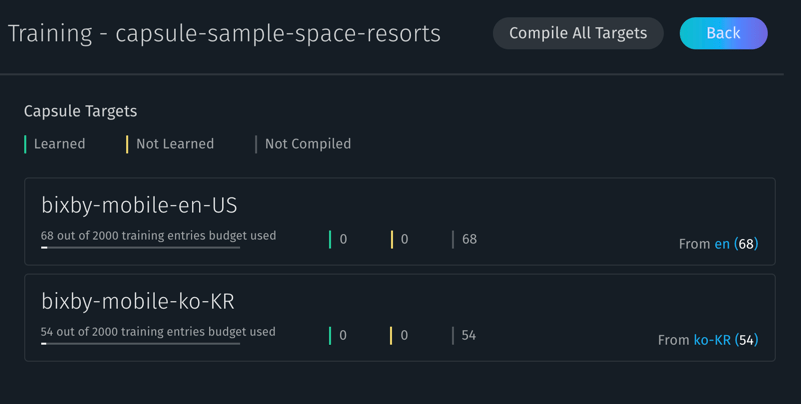
In addition, this screen shows status counts for each target, and whether your capsule's natural language (NL) model needs to be recompiled. You can recompile targets individually by clicking the "Compile" button that appears when you hover over a capsule target (this button will be dimmed if compiling that target is unnecessary), and compile all targets by clicking "Compile All Targets".
Training Limitations
The following sections list limitations to training your capsule.
Number of Training Entries
A capsule can have a "budget" of up to 2,000 training entries per target. A target is a specific combination of device, language, and region:
en: All devices, English language, all regionsbixby-mobile-en: Mobile devices, English language, all regionsbixby-mobile-en-US: Mobile devices, English language, US region
The 2,000-entry limit is shared across parent targets. For example, the en target is a parent of all English-speaking device targets such as the bixby-mobile-en, bixby-mobile-en-US, and bixby-other-en-US; if en had 1,000 entries in it, then bixby-mobile-en would inherit those entries, and could have up to 1,000 more. If en has 1,000 entries in it and bixby-mobile-en had 500 more, then bixby-mobile-en-US would inherit from both of its parents, and could add up to 500 more.
No Named Entities
Bixby does not have platform-level support for recognizing named entities. That means it won't automatically be able to distinguish between people, places, movie titles, etc. It is up to you to distinguish these entities in a domain-specific way, through training examples and vocabulary.
Reserved Utterances
There are several utterances that have specific meanings in particular situations. For example, "Next" while navigating a list will read the next item or page of items. When possible, create complete training examples to help distinguish between these reserved meta-commands. For example, train "Cancel my reservation" instead of just "Cancel" for English because "Cancel" clears conversation context in Bixby.
For the full list of meta-commands, see the Reserved Utterances reference.
In addition to reserved utterances for list navigation, Bixby also reserves common utterances for device and media control, such as canceling alarms or stopping music playback. Bixby will automatically handle the following kinds of actions, and you don't need to (and shouldn't!) create actions within your capsule to handle these situations:
- Stopping timer, alarm, reminder, calendar, or phone alerts/rings
- Decreasing, increasing, or setting volume level
- Scrolling
- Controlling media playback (previous, next, skip forward/back, fast-forward, rewind, pause, stop, resume, replay)
Automatic Speech Recognition and Text-to-Speech
Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) are useful Bixby capabilities for communicating with users. However, the natural language utterances you train and the vocabulary you add are only used in their specific capsule (although they might be used over time to help improve ASR and TTS performance).